I did and I used this summary with some bullets and some parts of text extracted from AWS papers and from come online courses like cloud guru, linux academy, udemy. To study concepts about AWS Architecting to Scale.
I hope it could be useful to someone.
Scaling in cloud is totaly related with Microservice architectures, this approach to software development to speed up deployment cycles, foster innovation and ownership, improve maintainability and scalability of software applications, and scale organizations delivering software and services by using an agile approach that helps teams to work independently from each othe
Microservices architectures are not a completely new approach to software engineering, but rather a combination of various successful and proven concepts such as:
- Agile software development
- Service-oriented architectures
- API-first design
- Continuous Integration/Continuous Delivery (CI/CD)
In many cases, design patterns of the Twelve-Factor App are leveraged for microservices.
Distributed Data Management
Monolithic applications are typically backed by a large relational database, which defines a single data model common to all application components. In a microservices approach, such a central database would prevent the goal of building decentralized and independent components. Each microservice component should have its own data persistence layer.
Distributed data management, however, raises new challenges. As a consequence of the CAP Theorem,distributed microservices architectures inherently trade off consistency for performance and need to embrace eventual consistency.
In a distributed system, business transactions can span multiple microservices. Because they cannot leverage a single ACID transaction, you can end up with partial executions. In this case, we would need some control logic to redo the already processed transactions. For this purpose, the distributed Saga pattern is commonly used. In the case of a failed business transaction, Saga orchestrates a series of compensating transactions that undo the changes that were made by the preceding transactions.
Saga execution coordinator:
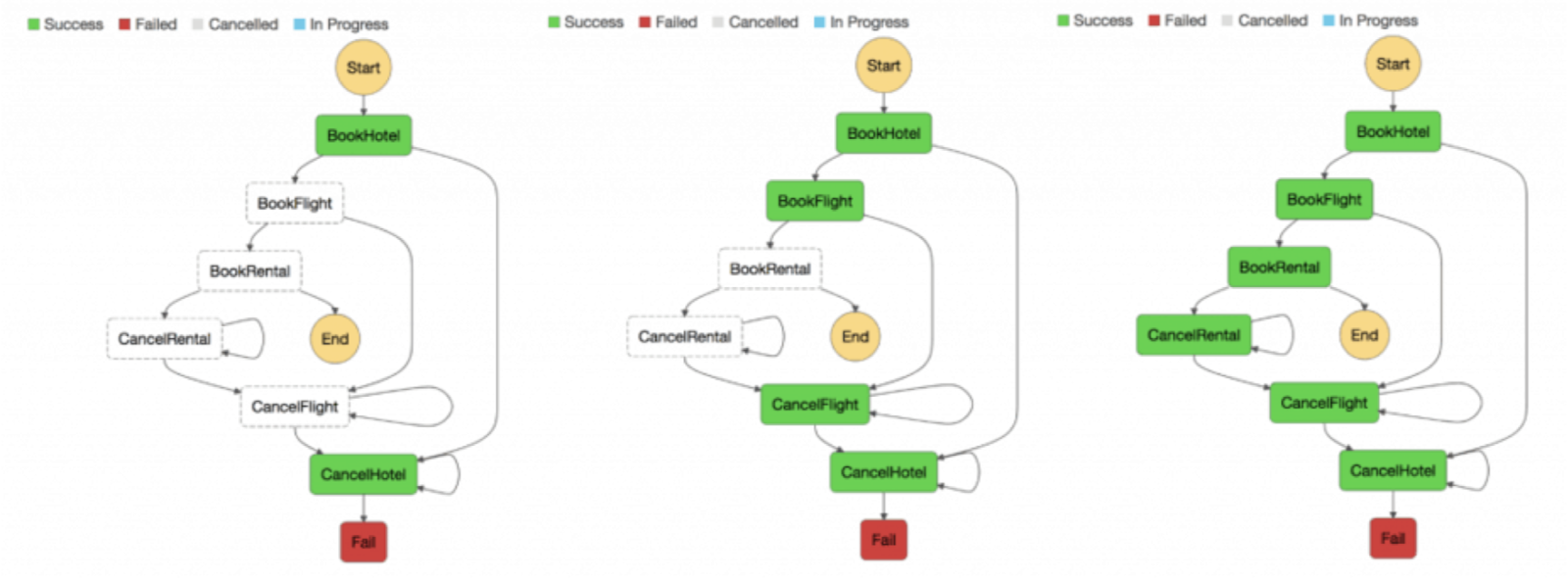
Loosely Coupled Architecture
Loosely couple architectures have several benefits but the main benefit in terms of scalability is atomic functional units. These discrete units of work can scale independently.
- Layers of abstraction
- Permits more flexibility
- Interchangeable components
- More atomic functional units
- Can scale components independetely
Horizontal vs Vertical Scaling
| Horizontal Scaling | Vertical Scaling |
| Add more instances as demand increase | Add more CPU and/or more RAM to existing instance as demand increase |
| No downtime required to scale up or scale down | Requires restart to scale up or down |
| Automatic using Auto-Scaling Groups | Would require scripting to automate |
| (Theoretically) Unlimited | Limited by increase sizes |
Auto-Scaling Groups
If your scaling is not picking up the load fast enough to maintain a good service level, reducing the cooldown can make scaling more dramatic and responsive
- Automatically provides horizontal scaling for your landscape.
- Triggered by an event or scaling actions to either launch or terminate instances.
- Availability, Cost and System Metrics can all factor into scaling.
Four Scaling options:
- Maintain- Keep a specific or minimum number of instances running
- Manual - Use maximum, minimum, or specific number of instances
- Schedule - Increase or decrease instances based on schedule
- Dynamic- Scale based on real-time metrics of the systems
Launch Configuration:
- Specify VPC and subnets for scaled instances
- Attach to a ELB
- Define a Health Check Grace Period
- Define size of group to stay at initial size.
- Use scaling policy which can be based from metrics
Scaling Types:
| Scaling Type | What | When |
| Maintain | Hands-off way to maintain X number of instances | “I need 3 instances always" |
| Manual | Manually change desired capacity via console or CLI | “My needs change so rarely that I can just manually add and remove" |
| Scheduled | Adjust min/max instances based on specific times | “Every Monday morning, we get a rush an our website" |
| Dynamic | Scale in response to behaviour of elements in the environment. | “When CPU utilization gets to 70% on current instances, scale up." |
Scaling Policies:
| Scaling | What |
| Target Tracking Policy | Scaled based on a predefined or custom metrics in relation to a target value |
| Simple Scaling Policy | Waits until health check and cool down period expires before evaluating new need. |
| Step Scaling Policy | Responds to scaling needs with more sophistication and logic. |
Scaling Cooldowns
- Configurable duration that give your scaling a chance to “come up to speed “ and absorb load.
- Default couldown period is 300 seconds.
- Automatically applies to dynamic scaling and optionally to manual scaling but not supported by scheduled scaling.
- Can override default couldown via scaling-specific cool down.
Kinesis
Kinesis Data Streams can immediately accept data that has been pushed into a stream, as soon as the data is produced, which minimises the chances of data loss at the producer stage.
The data does not need to be batched first.
They can also extract metrics, generate reports and perform analytics on the data in real-time, therefore the first two options are correct.
Kinesis Data Streams is not a long term storage solution as the data can only be stored within the shards for a maximum of 7 days. Also, they can't handle the loading of the streamed data directly into data stores such as S3.
Although data can be read (or consumed) from shards within Kinesis Streams using either the Kinesis Data Streams API or the Kinesis Consumer Library (KCL), AWS always recommend using the KCL. The KPL (Kinesis Producer Library) will only allow writing to Kinesis Streams and not reading from them. You can not interact with Kinesis Data Streams via SSH.
- Collections of services for processing streams of various data.
- Data is processed in “shards” - with each shard able to ingest 1000 records per second.
- A default limit of 500 shards, but you can request an increase to unlimited shards
- Record consists of Partitions Key, Sequence Number and Data Blob (up to 1MB).
- Transient Data Store - Default retention of 24 hours, bu can be configured for up to 7 Days.
Kinesis Video Streams

Kinesis Data Streams

Kinesis Data Analytics

Kinesis Data Streams Key Concepts


DynamoDB
Throughput :
- Read Capacity Units
- Write Capacity Units
Max item size is 400KB
Terminology:
- Partition: A physical space where DynamoDB data is stored.
- Partition key: A unique identifier for each record, sometimes called a Hash Key.
- Sort Key: In combination with a partition key, optional second part of a composite key that defines storage order, sometimes called a Range Key.
To determine the partitions, we need to know the table size, the RCUs and the WCUs. But we know we will at least have 3 partitions given the 25GB size ( 25 / 10 = 2.5 rounded up to 3 )
Partition Calculation:
- By Capacity: Total RCU/ 3000 + Total WCU/ 1000
- By Size: Total Size / 10 GB
- Total Partition: Round up for the MAX (By Capacity, By Size)



Wrong way to use Partition key with date and sort key with ID:

When ask for all the sensor readings for 2018-01-01, will search in the same partition.
In right way, Partition key with ID and Sort Key with date.

When ask for all the sensor readings for 2018-01-01, will search in all partition.
Auto Scaling for DynamoDB:
- Using target tracking method to try to stay close to target utilisation.
- Currently does not scale down if table’s consumption drops to zero.
- Workaround 1: Send request to the tables unit auto scales down.
- Workaround 2: Manually reduce the max capacity to be the same as minimum capacity.
- Also supports Global Secondary indexes- think of them like a copy of table.
Cloud Front
Behaviors allow us to define different origins depending on the URL path. This is useful when we want to serve up static content from S3 and dynamic content from an EC2 fleet for example for the same website.
- Can delivery content to your users faster by caching static and dynamic content at edge locations.
- Dynamic content delivery is achieved using HTTP cookies forwarded from your origin.
- Supports Adobe Flash Media Server’s RTMP protocol but you have to choose RTMP delivery method.
- Web distribution also supports media streaming and live streaming but use HTTP or HTTPS.
- Origins can be S3, EC2,ELB or another web server.
- Multiple origins can be configured.
- Use behaviour to configure serving up origin content based on URL paths.
Invalidation Requests
- Simply delete file from the origin and wait for the TTL to expire.
- Use the AWS Console to request invalidation for all content or a specific path such as /images/*
- Use the CloudFront API to submit an invalidation request.
- Use third-party tools to perform CloudFont invalidation (CloudBerry,Ylastic,CDN Planet, CloudFront Purge Tool)
Simple Notification Service (SNS)
- Enables a Publish/Subscribe design pattern.
- Topics = A channel for publishing a notification
- Subscription = Configuring and endpoint to receive messages published on the topic
- Endpoint protocols include HTTP(S), Email, SMS, SQS, Amazon Device Messaging (push notification )and Lambda

Simple Queue Service (SQS)
- Reliable, highly-scalable, hosted message queue service
- Available integration with KMS for encrypted messaging.
- Transient storage default 4 days, mas 14 days.
- Optionally supports First-in First-out queue ordering.
- Maximum message size of 256KB but using a special Java SQS SDK, you can have message as large as 2GB.
Amazon MQ
- Managed implementation of Apache ActiveMQ
- Fully managed and highly available within a region.
- ActiveMQ API and supports for JMS, NMS, MQQT, WebSocket.
- Design as a drop-in replacement for on-premises message brokers.
- Use SQS if you creating a new application from scratch.
- Use MQ if you want an easy low-hassle path to migrate from existing message brokers to AWS.
Lambda
- Allows you to run code on-demand without the need for infrastructure.
- Supports Node,js, Python, Java, Go and C#.
- Extremely useful option for creating rerverless architectures.
- Code is stateless and execute on an event basis (SNS,SQS, S3, DynamoDB Streams etc.).
- No fundamental limits to scaling a function since AWS dynamically allocates capacity in relation to events.

Simple Workflow Service (AWS SWF)
- Create distributed asynchronous system as workflows.
- Supports both sequencial and parallel processing.
- Tracks the state of your workflow which you interact and update via API.
- Best suited for humans enable workflow like a order fulfilment or procedural requests.
- AWS recommends new applications look like at step functions over SWF.

Example:

Step Functions
- Managed workflow and orchestration platform
- Scalable and highly available
- Define your app as state machine
- Create tasks, sequencial steps, parallel steps, branching paths or timers.
- Amazon State Language declarative JSON.
- Apps can interact and update the stream via Step Function API
- Visual interface describe flow and realtime status.
AWS Batch
Management tools for creating, managing and executing batch-oriented tasks using EC2 instances.
- Create a Computer Environment: Management to Unmanaged, Spot or On-Demand, vCPUs
- Create a Job Queue with priority and assigned to a Computer Environment
- Create Job Definition; Script to JSON, environment variables, mount points, IAM role, containers images. etc
- Schedule the Job
| When | Use Case | |
| Step Function | Out-of-the-Box coordination of AWS service components | Order Processing Flow |
| Simple workflow Service | Need to support external processes or specialized execution logic | Loan Application Process with Manual Review Steps |
| Simple Queue Service | Messaging Queue, Store and forward patterns | Image Resize Process |
| AWS Batch | Scheduled or reoccurring tasks that do not required heavy logic | Rotate Logs Daily on Firewall Appliance |
Elastic Map Reduce (EMR)
The Zoo

- Managed Hadoop framework for processing huge amount of data
- Also supports Apache Spark, HBase, Presto and Flink
- Most commonly used for log analysis, financial analysis or extract, translate and loading ETL activity.
- A Step is a programatic tasks for performing some process on the data
- A cluster is a collection of EC2 instances provisioned by EMR to run your steps
Components of AWS EMR

AWS EMR Process

An Overview of Traditional Web Hosting

The same kind of application on AWS

Security groups in a web application

Memcached vs. Redis
Memcached—a widely adopted in-memory key store, and historically the gold standard of web caching. ElastiCache is protocol-compliant with Memcached, so popular tools that you use today with existing Memcached environments will work seamlessly with the service. Memcached is also multithreaded, meaning it makes good use of larger Amazon EC2 instance sizes with multiple cores.
Redis—an increasingly popular open-source key-value store that supports more advanced data structures such as sorted sets, hashes, and lists. Unlike Memcached, Redis has disk persistence built in, meaning that you can use it for long-lived data. Redis also supports replication, which can be used to achieve Multi-AZ redundancy, similar to Amazon RDS.
Architecture with ElastiCache for Memcached

Architecture with ElastiCache for Redis

Reference:
- https://d1.awsstatic.com/whitepapers/aws-web-hosting-best-practices.pdf
- https://d0.awsstatic.com/whitepapers/architecture/AWS_Well-Architected_Framework.pdf
- https://d0.awsstatic.com/whitepapers/performance-at-scale-with-amazon-elasticache.pdf
- https://d1.awsstatic.com/whitepapers/microservices-on-aws.pdf
- https://acloud.guru/
Nenhum comentário:
Postar um comentário
Observação: somente um membro deste blog pode postar um comentário.